From evidence collection to validated findings.
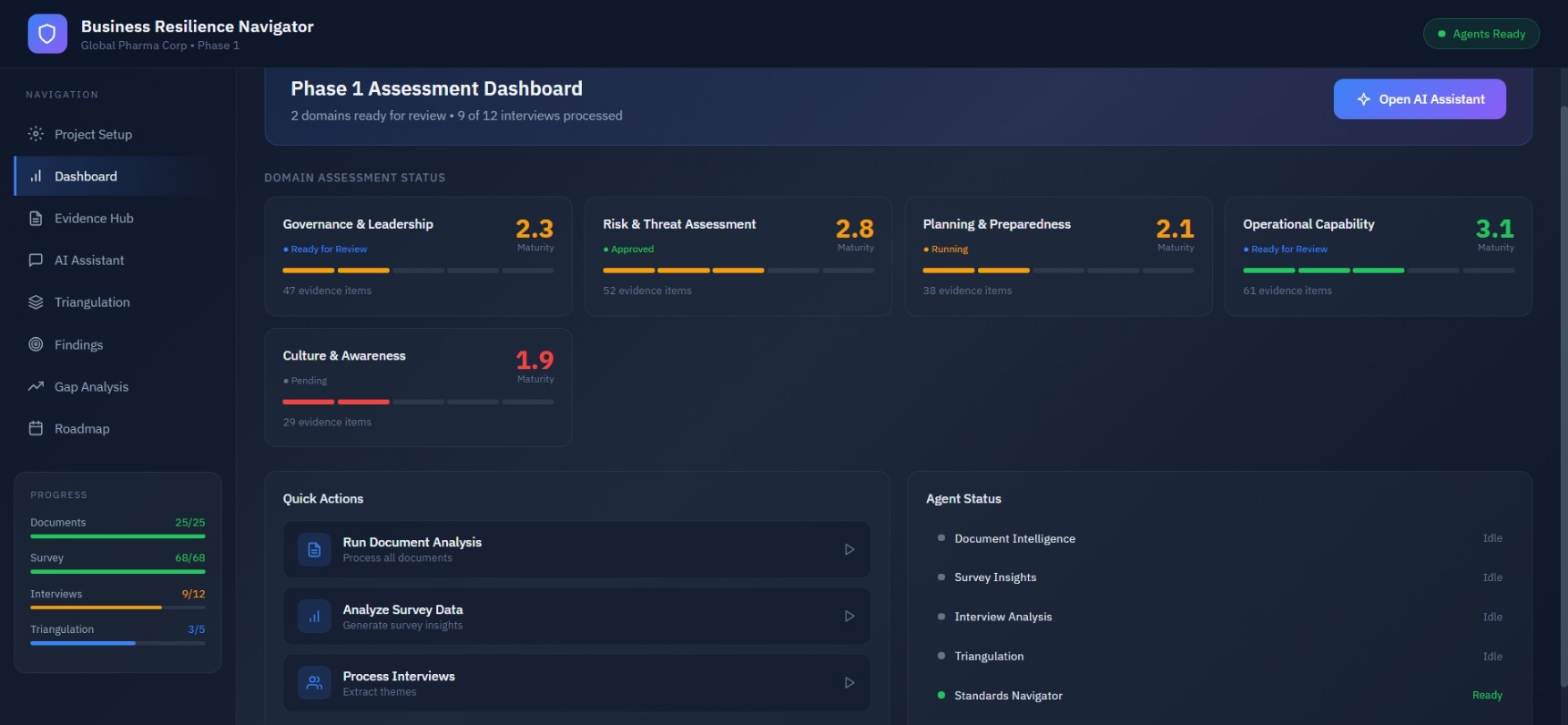
Consultant Dashboard
Central hub showing project setup, multi-agent status, and evidence collection progress. Track which AI agents are active, idle, or processing across documents, surveys, and interviews.
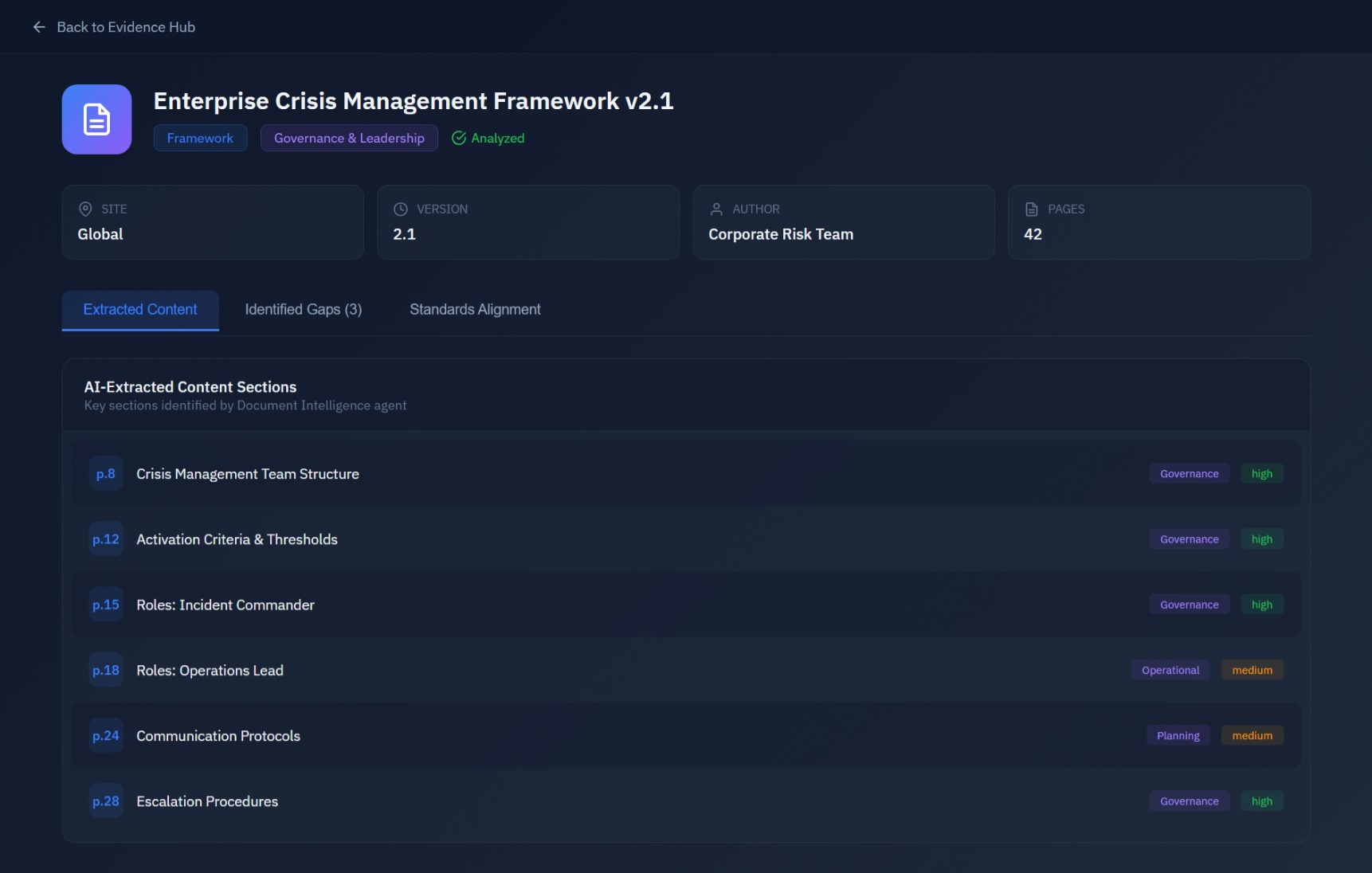
Document Intelligence Agent
Deep analysis of business continuity plans and frameworks. Extract key sections, identify gaps against standards (ISO 22301, BS 65000, BCI GPG), and map to resilience domains with line-level citations.
Survey Insights Agent
Function-by-function breakdown of survey confidence scores. Detect outliers, analyze question-level patterns, and surface perception gaps across organizational units with respondent metadata.

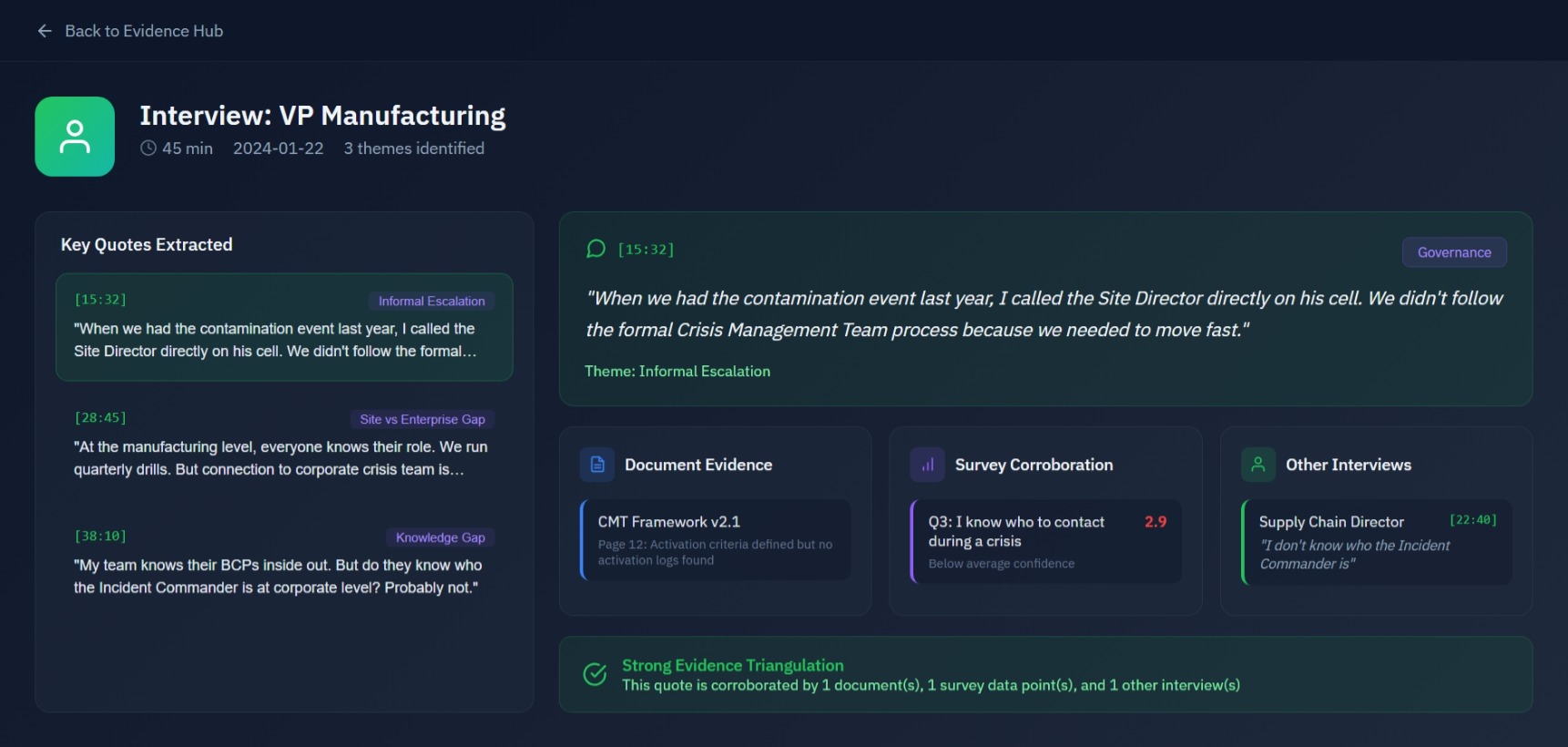
Interview Analysis Agent
Extract quotes from stakeholder interviews and cross-reference with documents and surveys. Link contradicting or confirming evidence across all three streams to validate operational reality.
Triangulation Dashboard
Unified view of validated findings with confidence scores. Review AI-generated insights marked as "Draft," add consultant notes, and approve findings before client delivery. Design-Perception-Reality framework in action.
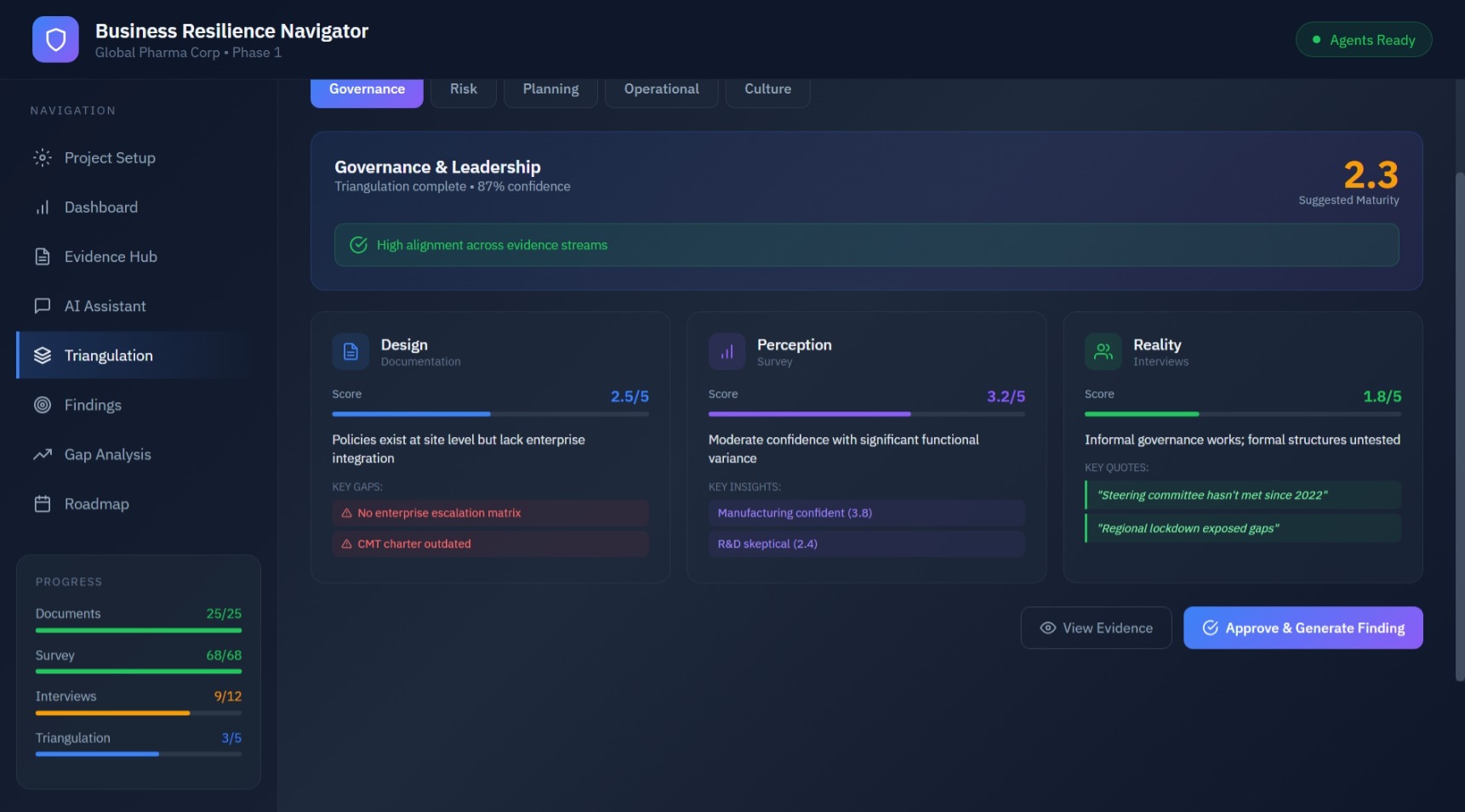
Assessment Findings
AI-generated and manual findings with consultant validation workflow. Track draft, reviewed, and approved status. Add maturity scores and link to governance domains with complete evidence traceability.
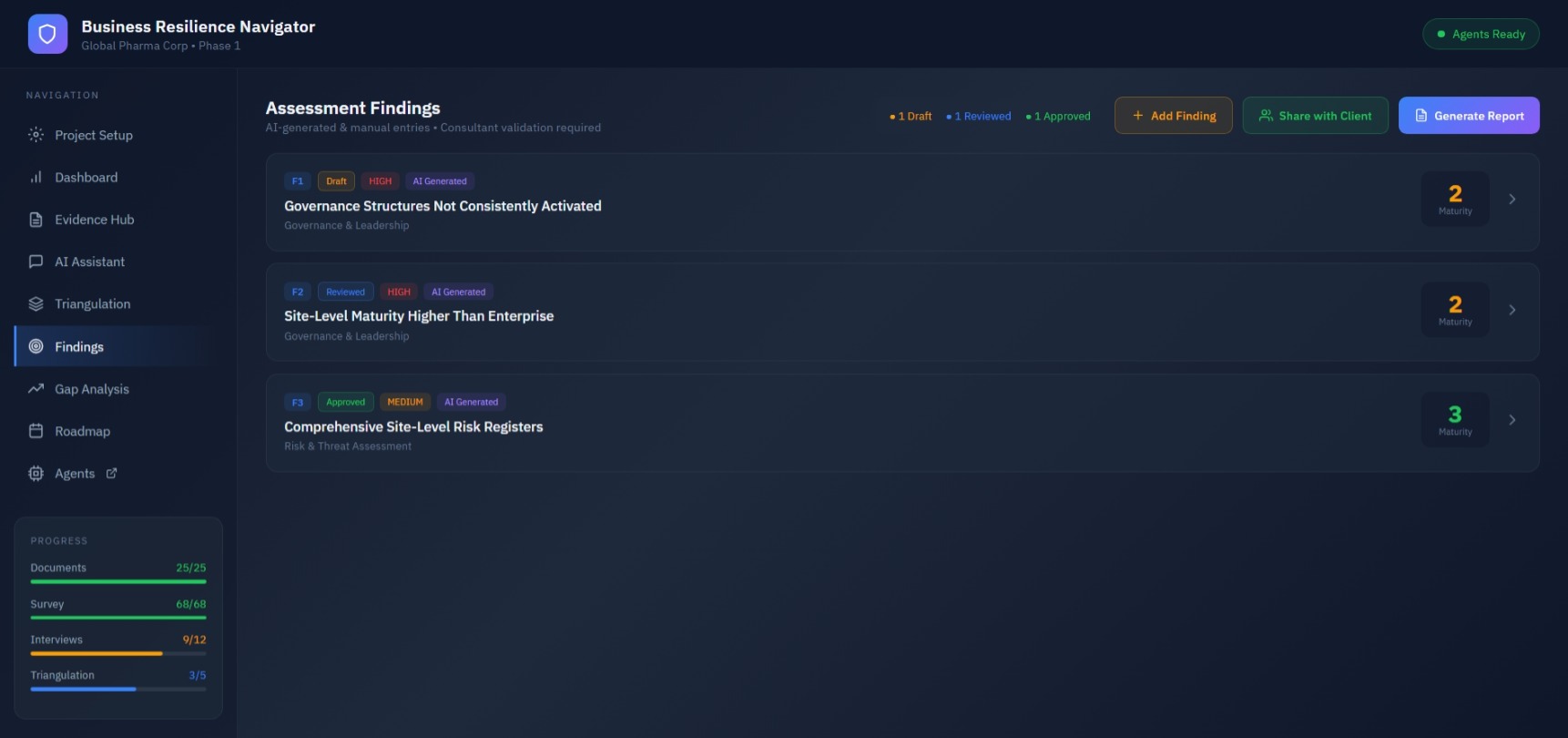
Gap Analysis
Compare current state to target maturity levels across resilience domains. View gaps by domain with effort and impact indicators, recommended actions to close gaps, and alignment to ISO 22301 clauses.
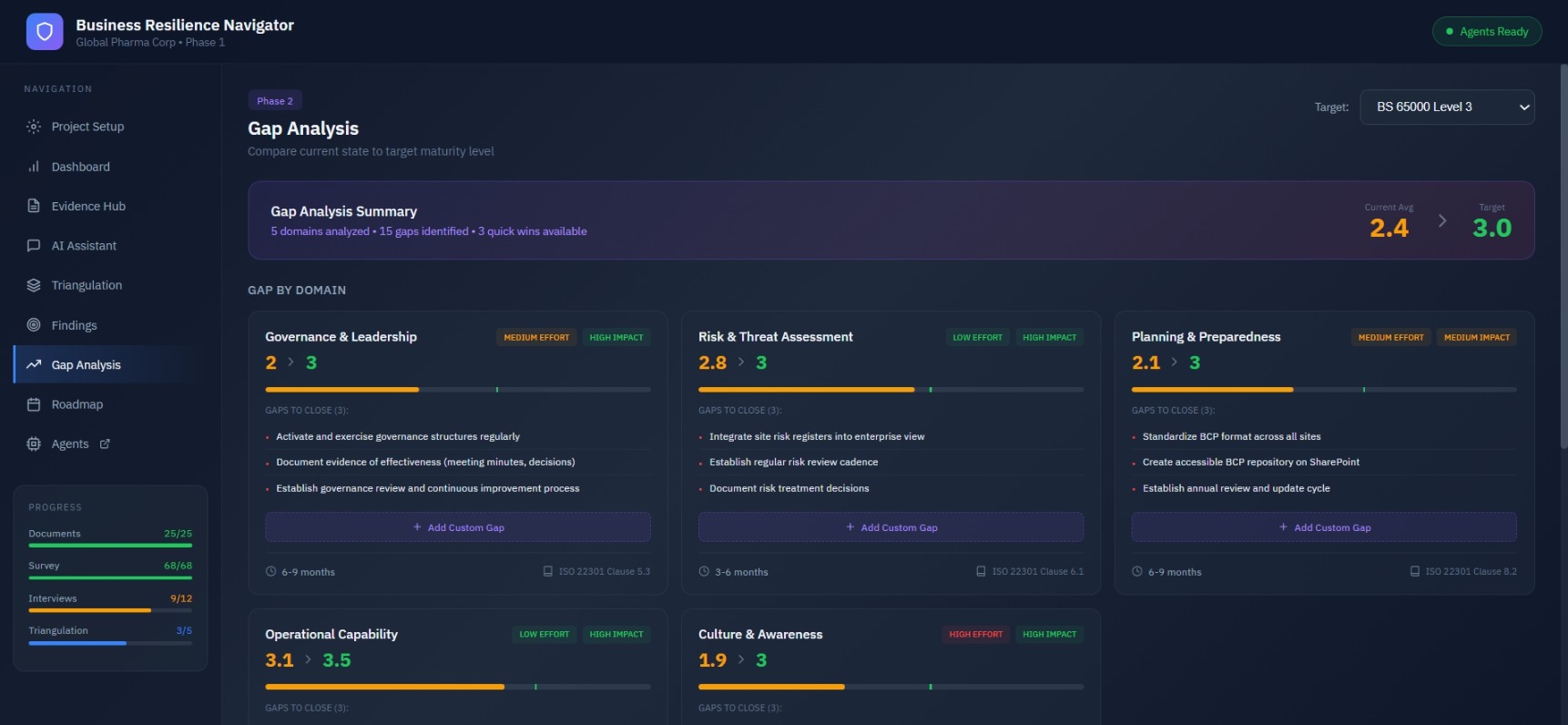
Implementation Roadmap
Timeline for closing gaps and achieving target maturity. View initiatives by quarter with quick wins and critical path items. Automated dependency detection and sequencing across Q1-Q4.
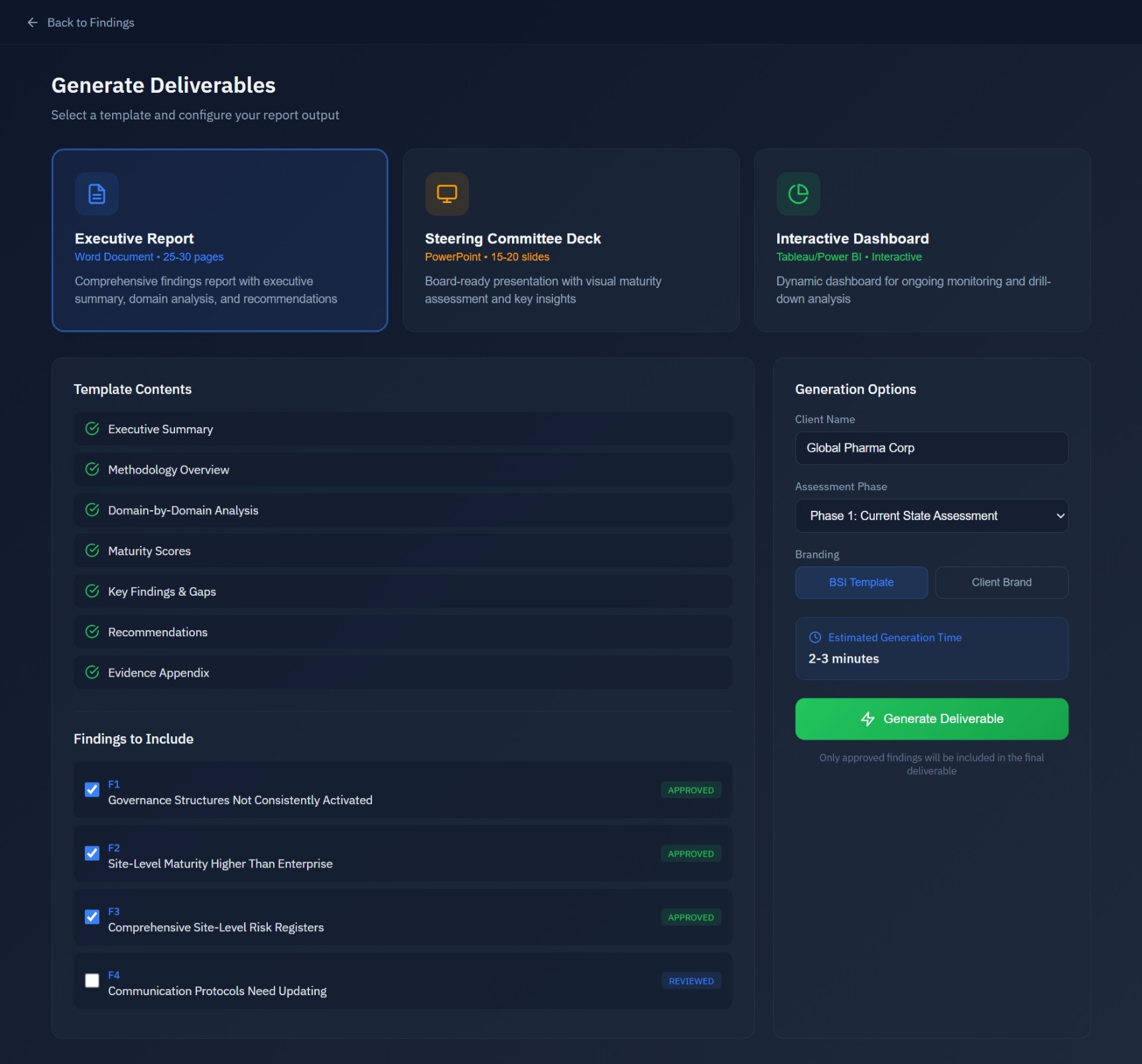
Deliverable Generation
Export to Word (executive reports), PowerPoint (board decks), or interactive dashboards. Select findings to include, customize templates, and generate client-ready deliverables with evidence citations.
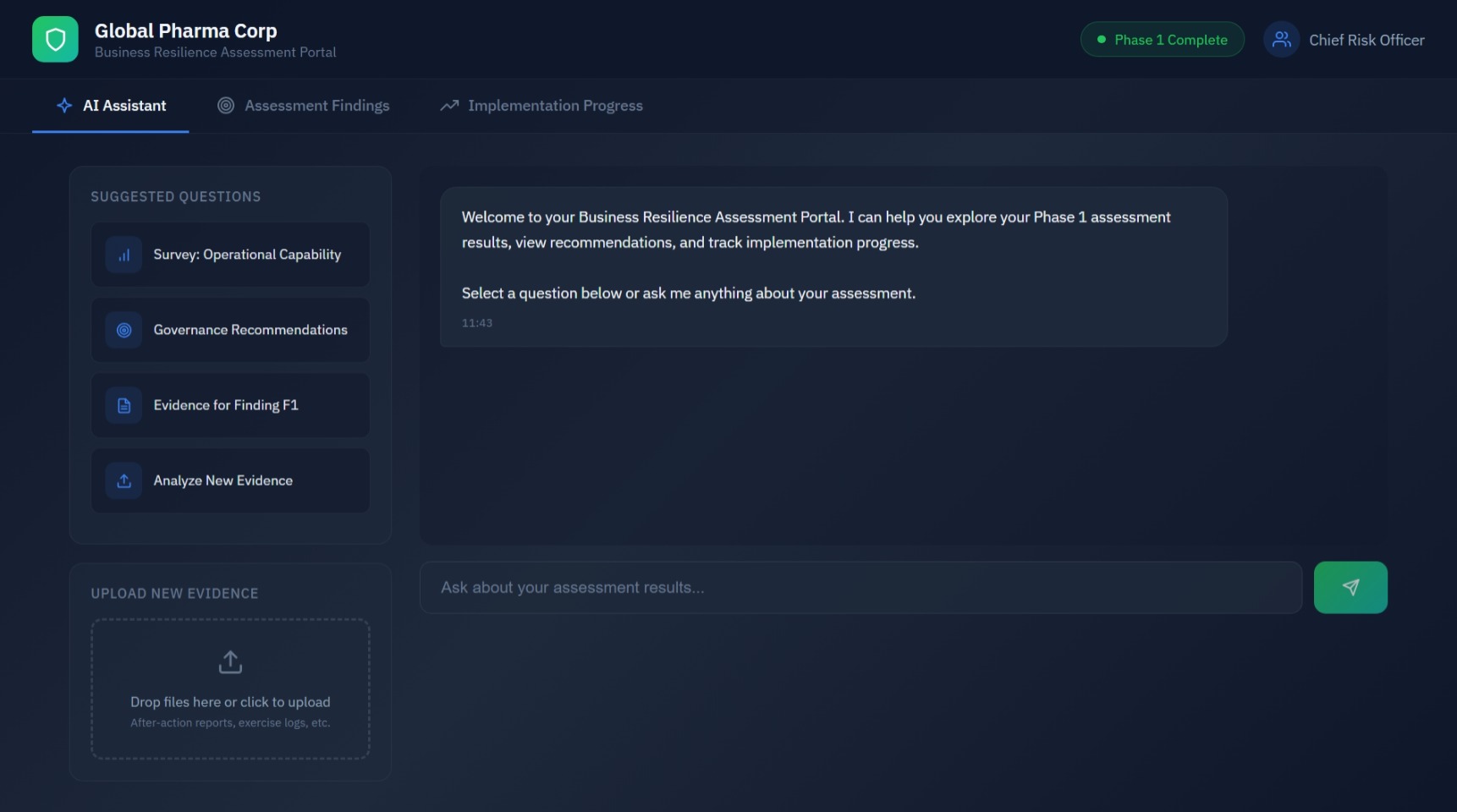
Client Portal
Client-facing AI assistant interface for exploring assessment results. Ask questions about survey responses, recommendations, and evidence. Upload new documents for real-time analysis.
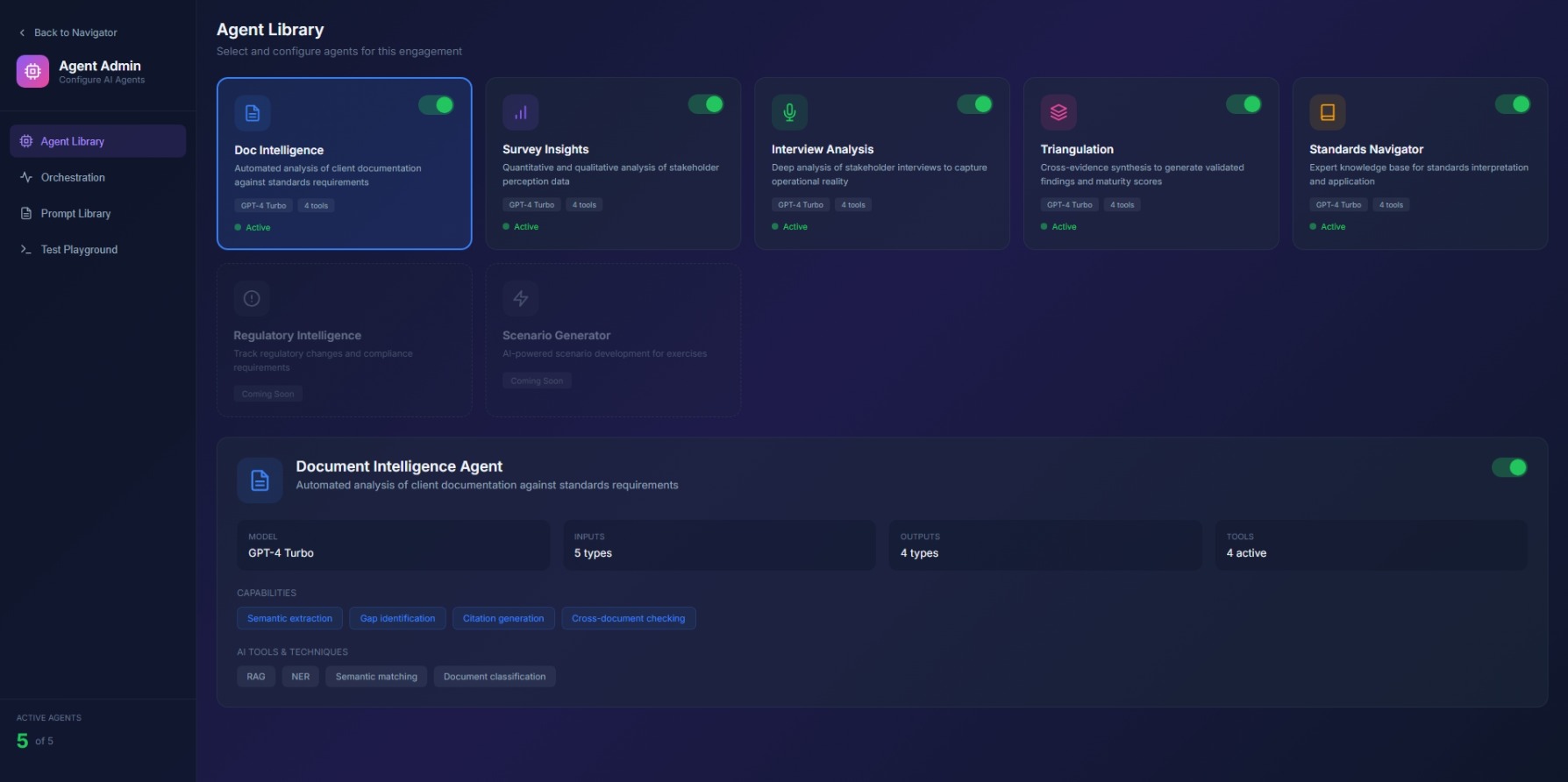
Agent Configuration
Select and configure agents required for augmented assessment workflows. DAG orchestration management console showing agent dependencies and execution status.